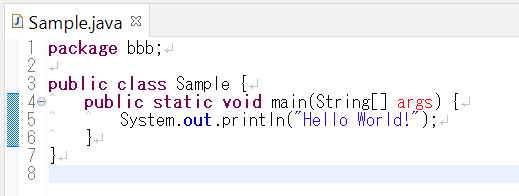
先日、SQL Serverであるテーブルに登録されている不要なテーブルを大量に削除するクエリを作成しました。
かなり省いておりますが、以下のような感じのクエリです。
DECLARE @delete_row INTEGER; SET @delete_row = 0; WHILE 1 = 1 BEGIN BEGIN TRAN DELETE TOP (50000) FROM dbo.Sample WHERE created_date < '2024-01-01'; SELECT @delete_row = @@ROWCOUNT; COMMIT TRAN IF @delete_row = 0 BEGIN BREAK END END
やっていることは、「dbo.Sample」というテーブルから「created_date」が'2024-01-01'より古いデータを50,000件ずつ削除して、削除する行が0件になったらループが終了するという感じです。
一度に大量データを削除すると、たとえ復旧モデルが「単純」でもトランザクションログが大変なことになりますので、少しずつ分けてコミットするようにしています。
そして、ここからが本題なのですが、上記クエリを実行してみたら、予想に反してトランザクションログがどんどん膨れ上がり、結果的にとんでもないサイズになってしまいました。
何故だろうと思って少し調べたら、原因はそのセッションで「暗黙的トランザクション」がONに設定されていたからでした。
以前、SSMSで以下の設定をしていたことを忘れておりました。

上記の設定をすると、暗黙的にトランザクションが開始されます。そのため、上記SQLのBEGIN TRAN~COMMIT TRANはネストしたトランザクションになっていたのです。
そのため、実際にはコミットが完了されておらず、結局すべての削除の処理が暗黙的トランザクションにより、まとめて処理される形になってしまっていたのでした。
原因が判明したので、上記クエリの冒頭に以下のSET句を追加しました。
SET IMPLICIT_TRANSACTIONS OFF
これで、再実行してみると以前のようなトランザクションログの肥大化がなくなりました。
暗黙的トランザクションの設定は思わぬデータ削除などを防ぎますが、注意して使わないと予想外の挙動が発生してしまうので注意が必要だと思いました。
最後までお読みいただきありがとうございました。今回はこの辺で失礼いたします。